




YouTubeチャンネルの動画が200本を超えると、再生リストの管理や動画の整理が大変になります。YouTube Studioだけでは一覧性に欠け、どの動画がどの再生リストに属しているか把握するのも困難です。
そこで今回は、YouTube APIを使って全動画情報を自動取得し、ホームページ掲載用のデータを効率的に作成する方法をご紹介します。この手法により、手作業でのコピペ作業から解放され、動画管理が格段に楽になります。
目的
主な目的は以下の2つです。
- 再生リストの管理: 動画が意図した再生リストに属しているか、あるいはどの再生リストにも属していない「迷子」の動画がないか、一覧で確認したかった。
- ウェブサイトへの掲載: YouTubeの再生リストはかなり使いづらいので、自身のウェブサイトに動画一覧を掲載して分かりやすくしたかった。そのためには、各動画の「タイトル」「URL」「説明文」などの情報が必要でした。
最終的には、この方法で出力したCSVファイルを使い、LLM(大規模言語モデル)にウェブサイト掲載用のMarkdownリストを自動生成させれば、いちいち手作業でコピペする必要がなくなると考えました。
使用するYouTube APIについて
まず、YouTubeのAPIには大きく分けて2種類あります。
- YouTube Data API v3: チャンネル、動画、再生リスト、コメントといったYouTubeの「データ」を取得・操作するためのAPIです。例えば、「チャンネルの全動画リスト」「動画のタイトルや再生回数」「どの再生リストにどの動画が入っているか」といった情報を取得できます。今回使用するのは、主にこちらのAPIです。
- YouTube Analytics API: 視聴者維持率、トラフィックソース、視聴者のデモグラフィック(年齢層・性別)など、自身のチャンネルに関するより詳細な「分析データ」を取得するためのAPIです。いわゆる「アナリティクス」画面の情報を、プログラムで一括取得したい場合に使います。
今回は、動画の基本情報や再生リストとの関連性を取得することが目的なので、YouTube Data API v3 を使います。
完成イメージ
成果物
今回の作成した成果物は以下のページになります。
取得できるデータ一覧
– 公開日、タイトル、動画URL
– 再生回数、高評価数、コメント数
– 動画の長さ、所属再生リスト
– タグ、サムネイルURL、説明文
手順
step1. 準備:Google Cloud PlatformでのAPI設定 (所要時間:約15分)
このスクリプトはYouTube Data API v3を利用するため、はじめにGoogle Cloudでの準備が必要です。この程度であれば無料枠で十分できますので、費用はかかりません。
- Google Cloudプロジェクトの作成: Google Cloud Consoleにアクセスし、新しいプロジェクトを作成します(既存のプロジェクトでもOKです)。
- APIの有効化: 作成したプロジェクトで「YouTube Data API v3」を検索し、有効化します。

- 認証情報の作成:
- 「APIとサービス」>「認証情報」に進みます。
- 「+ 認証情報を作成」から「OAuth クライアント ID」を選択します。
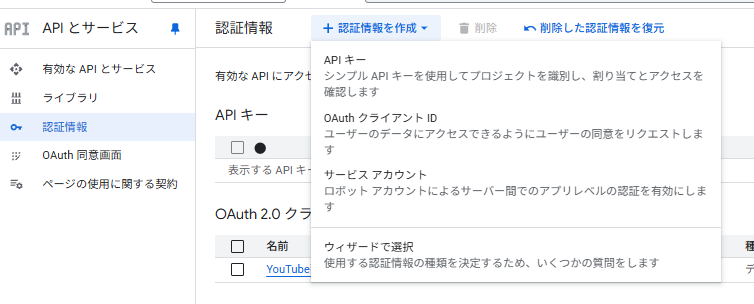
- アプリケーションの種類で「デスクトップアプリ」を選び、名前を付けて作成します。
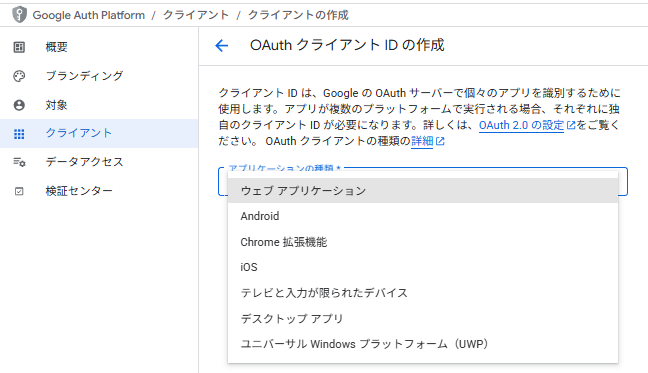
- 作成が完了すると、
client.jsonというファイルをダウンロードできるようになります。これを後ほど使います。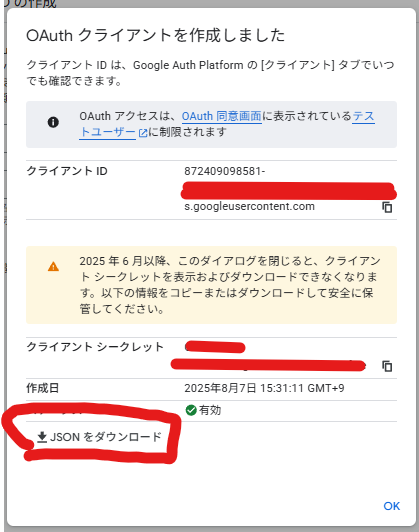
step2. 環境構築(所要時間:約10分)
次に、ローカル環境でスクリプトを実行する準備をします。Pythonで作成しているため、Windows/Mac/Linuxで動作します。ソースコードはこちらになります。
https://github.com/hiirofish/youtube-video-list
リポジトリのクローン
ターミナル(コマンドプロンプト)で以下のコマンドを実行し、ファイルをダウンロードし、google関連のライブラリをインストールします。
git clone https://github.com/hiirofish/youtube-video-list.git
cd youtube-video-list
pip install -r requirements.txt
client.jsonの配置:
先ほどGoogle Cloudからダウンロードした client.json ファイルを、このyoutube-video-listフォルダの中に移動させます。
チャンネルIDの設定:
youtube-video-listフォルダ内に channel_id.txt という名前で新しいファイルを作成します。そのファイルの中に、情報を取得したいご自身のYouTubeチャンネルIDを一行だけ記述して保存してください。
【チャンネルIDの確認方法】
- 一番簡単な方法: チャンネルのトップページURLが
https://www.youtube.com/channel/UCxxxxxxxxのような形式の場合、/channel/の後にあるUCから始まる文字列がIDです。 - ご自身のチャンネルの場合: YouTube Studio >「カスタマイズ」>「基本情報」で確認できます。
step3. データ取得(所要時間:約5分)
全ての準備が整ったら、以下のコマンドでスクリプトを実行します。
python youtube_video_list.py
ブラウザが起動すると、緑の矢印にURLアドレスが表示されるので、YouTube Data APIを有効にしたGoogleアカウントでの認証を求められます。一旦許可すると、token.jsonというファイルが生成されるので、2回目以降はこの作業は省略できます。処理が完了すると、フォルダ内に youtube_master_list.csv というファイルが生成されます。
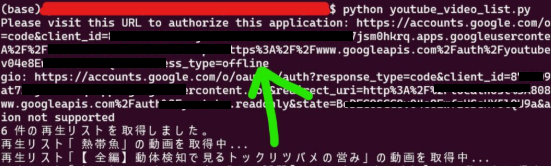
The authentication flow has completed. You may close this window.
取得できるCSVファイルについて
スクリプトが完了すると、以下のような情報を含んだ youtube_master_list.csv が生成されます。GoogleスプレッドシートやExcelで開けば、ソートやフィルタリングも簡単に行えるため、再生リストが空欄になっている「迷子」の動画を探すのも一目瞭然です。
- 公開日
- タイトル
- 動画URL
- 再生回数
- 高評価数
- コメント数
- 動画の長さ
- 所属再生リスト
- タグ
- サムネイルURL
- 説明文
csvファイルをGoogle Driveにアップロードして、スプレッドシートとして開くと以下のように見やすい形になります

その後は、ご自身の用途に合わせてデータを活用してください
wordpress用のホームページ作成
以下はプロンプトの参考例です。再生リストが「トックリツバメのヒナ 成長の瞬間【ショートハイライト】」で、開始番号がDAY56移行の動画をwordpressにコピペで貼り付けできるようにした例です。youtube内の説明の1行に軽いコメントを毎回入れているので、それを抜き出して貼り付けするようにしてます。これをyoutube_master_list.csvを添付して実行するだけです。claude sonnet 4を使ってます。
YouTubeマスターリストCSVファイルから、特定の再生リストのDay XX以降の動画を抽出し、WordPress(Gutenberg)用のMarkdownコードを生成します。
必要な情報
- 対象再生リスト名: (例:
トックリツバメのヒナ 成長の瞬間【ショートハイライト】)- 開始Day番号: (例:56)
- CSVファイル: YouTube APIで取得した動画マスターリスト
出力形式
markdown
## 観察記録 セカンド ### Day XX #### 「」内タイトル 説明文の先頭行 [](動画URL)プロンプト
添付されたYouTubeマスターリストCSVから、「{再生リスト名}」のDay {開始番号}以降の動画を対象に、WordPress Gutenberg用のMarkdownコードを生成してください。 【処理手順】 1. CSVを読み込み、指定した再生リストの動画のみを抽出 2. タイトルからDay番号を抽出(正規表現: /Day\s*(\d+)/i) 3. タイトルから「」内のテキストを抽出(正規表現: /「([^」]+)」/) 4. 説明文の先頭行を抽出(改行で分割して最初の行) 5. Day番号でソート・グループ化 6. 指定した開始番号以降の動画のみを対象とする 【出力構造】 - H2: "観察記録 セカンド" - H3: "Day XX"(Day番号のみ) - H4: 「」内のタイトルテキスト - コメント: 説明文の先頭行 - 画像リンク: `[](動画URL)` 【注意点】 - 同じDay番号に複数動画がある場合は、H3の下にH4を複数配置 - Day番号順に並べる - Markdown形式で出力(Gutenbergで編集しやすくするため) - 「」がないタイトルの場合はタイトル全体を使用 再生リスト名: {ここに再生リスト名を入力} 開始Day番号: {ここに開始番号を入力}使用例
添付されたYouTubeマスターリストCSVから、「トックリツバメのヒナ 成長の瞬間【ショートハイライト】」のDay 56以降の動画を対象に、WordPress Gutenberg用のMarkdownコードを生成してください。 【処理手順】 1. CSVを読み込み、指定した再生リストの動画のみを抽出 2. タイトルからDay番号を抽出(正規表現: /Day\s*(\d+)/i) 3. タイトルから「」内のテキストを抽出(正規表現: /「([^」]+)」/) 4. 説明文の先頭行を抽出(改行で分割して最初の行) 5. Day番号でソート・グループ化 6. 指定した開始番号以降の動画のみを対象とする 【出力構造】 - H2: "観察記録 セカンド" - H3: "Day XX"(Day番号のみ) - H4: 「」内のタイトルテキスト - コメント: 説明文の先頭行 - 画像リンク: `[](動画URL)` 【注意点】 - 同じDay番号に複数動画がある場合は、H3の下にH4を複数配置 - Day番号順に並べる - Markdown形式で出力(Gutenbergで編集しやすくするため) - 「」がないタイトルの場合はタイトル全体を使用 再生リスト名: トックリツバメのヒナ 成長の瞬間【ショートハイライト】 開始Day番号: 56
以下のようなmarkdownファイルが生成されるのでwordpressの適当なブロックに張り付けしたら完了です。
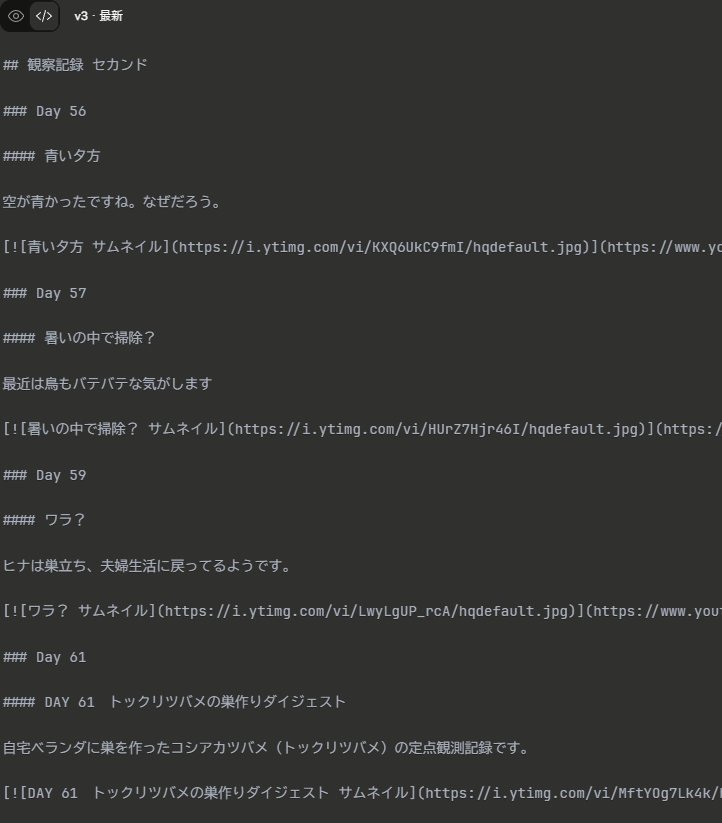
この方法によって生成されたページが最初に紹介したページになります。
まとめ
YouTube APIを活用することで、200本を超える動画の管理を大幅に効率化できました。従来なら数時間かかっていた動画整理作業が、わずか35分程度で完了するようになります。
この方法のメリット:
- 全動画情報を一括取得してCSV化
- 再生リスト管理の見える化
- LLMと連携したMarkdown自動生成
- WordPressへの簡単な記事投稿
特に、動画と再生リストの関連性を一覧で確認できるため、「迷子」の動画を簡単に発見できる点は大きな価値があります。また、LLMを活用することで、技術的な知識が少なくてもツールを作成・カスタマイズできるようになりました。 YouTubeチャンネルの運営効率化を検討している方は、ぜひ試してみてください。

