はじめに
この記事では、ローカルPCで手軽に大規模言語モデル(LLM)を試せる「LM Studio」を使い、20B(200億パラメータ)クラスのオープンソースLLM(本記事では openai/gpt-oss-20b として表示されるモデル)を VRAM 8GB の RTX 3060 Ti で動作させた事例を紹介します。
また、Windows上で起動したLM Studioのサーバー機能に対し、WSL (Windows Subsystem for Linux) 2からアクセスする際に少し工夫が必要だったため、その手順も詳しく解説します。
環境
ハードウェア
- GPU: NVIDIA RTX 3060 Ti (8GB)
- CPU: Intel Core i7-12700
- メモリ: 32GB (16GBでも十分動作すると思われます)
ソフトウェア
- OS: Windows 11
- WSL: WSL2 (Ubuntu)
- LLM実行環境: LM Studio 0.3.x
- モデル: 20BクラスのLLM(GGUF形式、GPUオフロード使用)
LM Studioの使い方
ダウンロードとインストール
以下のサイトからダウンロードします。
https://lmstudio.ai/
3つの選択肢が出てきますが、後から変更できますので、デフォルトのDeveloperを選択します。
以下のOSSをDLするように勧められるので一旦、これをDLします。12GBあるのでしばらく待ちます。
完了したら、画面上部にgpt-oss-20bが表示されていることを確認します。
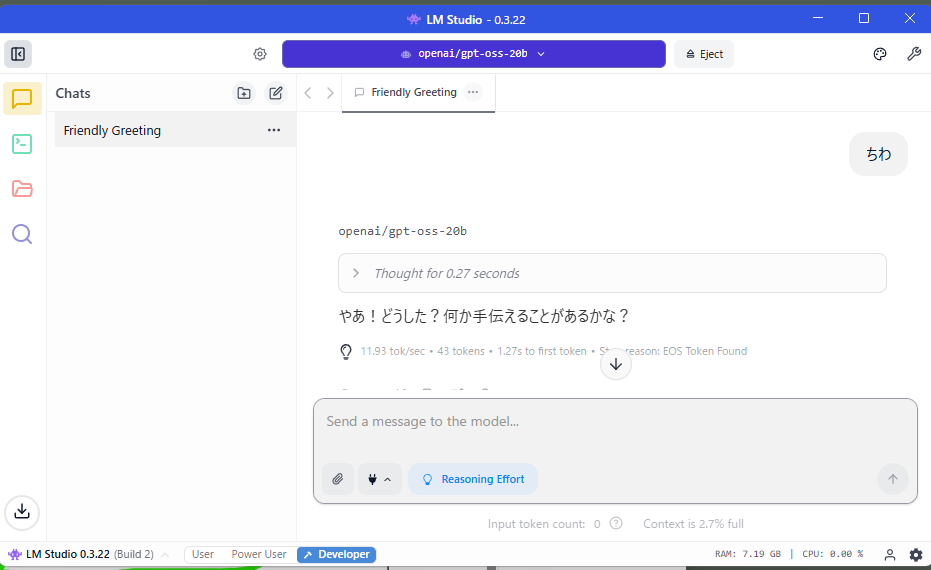
以下のように回答が返ってくればOK。
うんちく
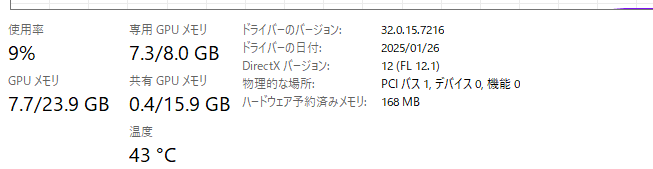
ここで特筆なのが、GPUメモリが8GBしかないのに動作した点です。11token/s程度ですが、20bのモデルが動くことがすごい。
これには量子化という技術が使われています。単純計算だと、FP16だと200億パラメータ (20b)だと200億パラメータ*2バイトなので、40GBのgpuメモリが必要です。全然足りていません。パラメータサイズを16bitから4bitに下げることで、1/4程度の10GBになります。ですが、今回は8GBしかないので、それでも足りません。
それに加えて、LM StudioはGPUオフロードという機能を使っていて、VRAMと通常のRAMを併用して足りていないところを一般メモリを代替して動作させます。GPUとRAM間の通信が発生するので遅くなってしまいますが、動作するということです。それでも、20bが11token/sで動くことがとんでもない。なので、GPUスペックがいまいちという方は性能が落ちますが、LM Studioを使うことで体験することは可能です。
ちなみにLM StudioはRAG(拡張検索)が5つまでのファイルに対応しています。手持ちファイルから情報を入手したり調べる方法です。これを使えば、手順書を入れて、ローカルで読み込むということもできます。クラウドだとNotebook LMのような機能にあたります。

外部アプリからアクセスする方法(windows)
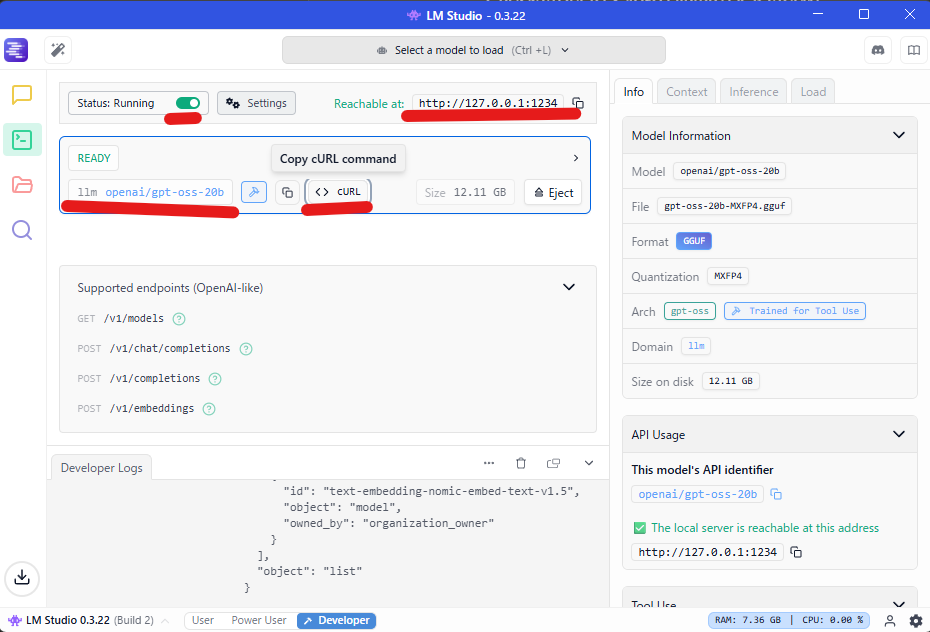
LM Studioは、OpenAI API互換のサーバー機能を持っています。これを有効にすることで、自作のアプリケーションからLLMを呼び出せます。
Status RunningというチェックボックスをONにします。モデルは先ほどすでにgpt-oss-20bがセットされてると思いますので、これだけで準備完了です。
WSLの設定
C:\Users\<ユーザー名>\.wslconfig
このファイルに以下の設定をすることでwslも同じネットワークに参加することができます。わざわざ、別のネットワークからアクセスする必要なかったです。
[wsl2]
networkingMode=mirrored
以下の内容を備忘録として残してますが、大半は不要です。wslで実行というところまで飛んでください。
以下はwslを外部ネットワーク(デフォルト)にしたまま使う場合
次にPowershellから以下のコマンドを打ちます。Rechable atの部分にアドレスが表示されているので、127.0.0.1:1234を使って、疎通ができるかを確認します。ちなみに、このアドレスはlocalhostでも同じです。
Invoke-RestMethod -Uri http://127.0.0.1:1234/v1/models
以下のような結果が返ってくればOK。
{@{id=openai/gpt-oss-20b; object=model; owned_by=organization_owner}, @{id=text-embedding-nomic-embed-text-v1.5; obj…
次に、curlの部分にサンプルプログラムがあるので、これを実行してみます。curlも使えますが、powre shellなので少しだけ弄って。以下のようなコードを実行します。貼り付けするだけです。コマンドが切れた場合はENTERを押してください。
$headers = @{"Content-Type" = "application/json"}
$body = @{
model = "openai/gpt-oss-20b"
messages = @(
@{
role = "system"
content = "Always answer in rhymes. Today is Thursday"
},
@{
role = "user"
content = "What day is it today?"
}
)
temperature = 0.7
max_tokens = 100
stream = $false
} | ConvertTo-Json -Depth 10
$response = Invoke-RestMethod -Uri "http://localhost:1234/v1/chat/completions" -Method Post -Headers $headers -Body $body
$response.choices[0].message.content以下のようにあ回答が返ってくると思います。とりあえず、win上では動作しましたね。ようやく本題ですが、wslのpythonから動作するようにします。
PS C:\Users\hiiro> $response.choices[0].message.content
It’s Thursday, not a Monday or a Tuesday—
A mid‑week pause before the weekend’s easy sway!
LM Studioはモデルをロードしてからバックグランドで動作し続けますので不要になったらタスクマネージャから終了したほうが良いかもしれません。(右下のバックグランドアプリのランチャーからでも終了させることができます。)
外部アプリからアクセスする方法(WSL)
ここからが本題です。WSLからWindowsホストで実行中のLM Studioにアクセスするには、ネットワークとファイアウォールの設定が必要です
wslから見たときのwindowsホストのIPアドレス
まず、Windows側でipconfigコマンドを実行し、WSL用の仮想ネットワークアダプターのIPアドレスを調べます。
ipconfig
以下のよう仮想アドレスが表示されるはずです。これに対して設定をしていきます。
この172.23.x.1がWSLから接続する際に使用するIPアドレスです。

ポートフォワーディング設定
LM Studioのサーバーは、セキュリティのため 127.0.0.1 (localhost) からのアクセスしか受け付けません。そこで、WSLから 172.23.16.1:1234 に来た通信を、Windowsが 127.0.0.1:1234 に転送するよう設定します。
管理者として開いたPowerShellで、以下のコマンドを実行します。listenaddressには先ほど控えたIPアドレスを指定してください。。
netsh interface portproxy add v4tov4 listenaddress=172.23.16.1 listenport=1234 connectaddress=127.0.0.1 connectport=1234
実施後、以下コマンドで確認します。
netsh interface portproxy show all
以下のような結果になればwslからの1234ポートに対してポートフォワーディング設定の感k量です。
Listen on ipv4: Connect to ipv4:
Address Port Address Port
————— ———- ————— ———-
172.23.16.1 1234 127.0.0.1 1234
ファイアウォール設定
wsl上で同様にコマンドを叩いてもうまくいきません、まずはファイヤウォールの設定を見てみます。以下のようにTCP/UDPクエリーがブロックされてしまっていました。
Get-NetFirewallRule -DisplayName “*LM Studio*”
Name: TCP Query User{…}C:\users\hiiro\…\lm studio.exe Action: Block ← これが問題だった!
Name: UDP Query User{…}C:\users\hiiro\…\lm studio.exe Action: Block ← これも問題!
そこで以下のようにブロックルールを削除してから、変更します。
Remove-NetFirewallRule -DisplayName “lm studio.exe”
次に、WSLのIPアドレス帯域からのみTCPポート1234への内向き通信を許可する、新しいルールを作成します。これによりセキュリティが向上します。
New-NetFirewallRule -DisplayName “LM Studio WSL Only” -Direction Inbound -Protocol TCP -LocalPort 1234 -RemoteAddress 172.23.0.0/16 -Action Allow
確認するためのコマンドは以下の二つです。
Get-NetFirewallRule -DisplayName “LM Studio WSL Only” | Format-List DisplayName, RemoteAddress, Action
Get-NetFirewallRule -DisplayName “LM Studio WSL Only” | Get-NetFirewallAddressFilter
この実行結果はいかのようになります。
PS C:\Users\hiiro> Get-NetFirewallRule -DisplayName “LM Studio WSL Only” | Format-List DisplayName, RemoteAddress, Action
DisplayName : LM Studio WSL Only
Action : AllowPS C:\Users\hiiro> Get-NetFirewallRule -DisplayName “LM Studio WSL Only” | Get-NetFirewallAddressFilter
LocalAddress : Any
RemoteAddress : 172.23.0.0/255.255.0.0
wslで実行
以上の設定が終われば、curlコマンドで確認しましょう。
wslでmirroreの設定をした場合
curl http://localhost:1235/v1/models
設定しなかった場合はこちら。
curl http://172.23.16.1:1234/v1/models以下のjsonが返却されれば設定はOKです。
{
“data”: [
{
“id”: “openai/gpt-oss-20b”,
“object”: “model”,
“owned_by”: “organization_owner”
},
{
“id”: “text-embedding-nomic-embed-text-v1.5”,
“object”: “model”,
“owned_by”: “organization_owner”
}
],
“object”: “list”
次に簡単なpythonコードをで動作確認します。サンプルコードを添付します。アドレスはPC環境ごとによって変わります。
#!/usr/bin/env python3
"""
シンプルなLM Studio性能測定スクリプト
"""
import requests
import time
import sys
def test_lm_studio(prompt, base_url="http://172.23.16.1:1234", max_tokens=100):
"""LM Studioにリクエストを送信して性能を測定"""
headers = {"Content-Type": "application/json; charset=utf-8"}
data = {
"model": "openai/gpt-oss-20b",
"messages": [
{"role": "user", "content": prompt}
],
"temperature": 0.7,
"max_tokens": max_tokens,
"stream": False
}
print(f"\nPrompt: {prompt}")
print("-" * 50)
start_time = time.time()
try:
response = requests.post(
f"{base_url}/v1/chat/completions",
headers=headers,
json=data,
timeout=60
)
response.raise_for_status()
end_time = time.time()
result = response.json()
content = result['choices'][0]['message']['content']
# トークン情報
usage = result.get('usage', {})
completion_tokens = usage.get('completion_tokens', 0)
total_time = end_time - start_time
tokens_per_second = completion_tokens / total_time if total_time > 0 else 0
# 結果表示
print(f"Response: {content}")
print("-" * 50)
print(f"Time: {total_time:.2f}s")
print(f"Tokens: {completion_tokens}")
print(f"Speed: {tokens_per_second:.1f} tokens/s")
return tokens_per_second
except Exception as e:
print(f"Error: {e}")
return 0
def main():
# 接続確認
base_url = "http://172.23.16.1:1234"
try:
response = requests.get(f"{base_url}/v1/models", timeout=2)
if response.status_code == 200:
print(f"✓ Connected to LM Studio at {base_url}")
else:
print("Error: Cannot connect to LM Studio")
sys.exit(1)
except:
print("Error: Cannot connect to LM Studio")
print("Make sure LM Studio is running and the IP is correct")
sys.exit(1)
# テスト実行
print("\n" + "=" * 50)
print("LM Studio Simple Benchmark")
print("=" * 50)
# いくつかのプロンプトをテスト
prompts = [
("Hello, how are you?", 50),
("Pythonで素数を判定する関数を書いて", 100),
("AIの利点を3つ挙げて", 100),
]
speeds = []
for prompt, max_tokens in prompts:
speed = test_lm_studio(prompt, base_url, max_tokens)
if speed > 0:
speeds.append(speed)
print()
# 平均速度
if speeds:
print("=" * 50)
print(f"Average speed: {sum(speeds)/len(speeds):.1f} tokens/s")
print("=" * 50)
if __name__ == "__main__":
# コマンドライン引数があればそれを使用
if len(sys.argv) > 1:
prompt = " ".join(sys.argv[1:])
test_lm_studio(prompt)
else:
main()結果、平均で 8.4 tokens/s となりました。チャットでの利用には少し待たされる感じはありますが、VRAM 8GBのGPUでこれだけの規模のモデルがローカルで動くというのは驚きです。
参考までに、RTX 4080 Laptop(12GB)で試したところ、20token/s程度でした。20tokenあれば、一般的な簡潔な回答が100字程度だとすると、5秒程度待つ感じですね。

まとめ
- LM Studioは量子化とGPUオフロード機能により、VRAMが8GBのような比較的少ない環境でも20BクラスのLLMを動作させることができた。
- WSLからWindowsホスト上のLM Studioサーバーにアクセスするには、
netshによるポートフォワーディングと、ファイアウォールの許可設定が必要だった。 - 20Bクラスのモデルは、少し前の
gpt-3.5-turboに匹敵する、あるいはそれ以上の応答品質を感じることもあり、ローカルマシンでプライベートなLLM体験を楽しむ選択肢として非常に有望だと感じた。